


ChatGPT by OpenAI came crashing into the world on November 30, 2022, and quickly captured everyone’s imagination, including that of businesses and lawyers eager to capitalize on the many ways artificial intelligence (AI) has been predicted to fundamentally change the way business is done, including how law is practiced. In this article, we offer a quantifiable look at whether GPT-4 is likely to live up to these expectations in the legal context and, more specifically, as it relates to document review in e-discovery.
ChatGPT is a large language, generative AI model, which means it can absorb a large quantity of written information and then generate new, original content after receiving a prompt from the user. ChatGPT is particularly interesting for legal practitioners because its generative capabilities have the potential to both alter and enhance attorneys’ current practices. For example, most in the legal community have heard by now the cautionary tale of lawyers who tried unsuccessfully to use ChatGPT to write legal briefs and were subsequently sanctioned by a federal district court. But that mishap certainly does not seal ChatGPT’s fate in the legal field; rather, it is an unfortunate example of the inexperienced use of a new technology without developing an understanding of its strengths and weaknesses.
Indeed, for e-discovery practitioners, ChatGPT and similar generative AI may cause a sea change in the not-so-distant future in how eDiscovery work is done. Specifically, ChatGPT’s evaluative and responsive capabilities have the potential to successfully replace or augment functions that are historically performed by attorneys or traditional evaluative tools like technology assisted review (TAR).
Shortly after the introduction of ChatGPT, OpenAI released a more advanced version of the technology, GPT-4, on March 14, 2023. This newer model is multimodal, which means it can make predictions on both text and images, while the original ChatGPT technology is limited to text only. GPT-4 pushed the boundaries of the technology’s performance even further in a number of ways. Specifically, GPT-4 outperformed ChatGPT across many tasks, exams, and benchmarks. For example, GPT-4 scored in the 90th percentile of the Uniform Bar Exam, while ChatGPT scored in only the 10th percentile. Currently, only the text model of this technology is supported in Microsoft Azure, but the vision capable version will be released in the near future.
Conducting a GPT-4 Experiment
To better understand the current capabilities of GPT-4 for e-discovery, we collaborated with global legal technology company Relativity to evaluate how standard GPT-4 would perform in coding documents for responsiveness. To perform this experiment, Sidley identified a prior, closed case in which documents had been coded by human reviewers for responsiveness. The now closed case involved a subpoena related to potential violations of the Anti-Kickback Statute. The subpoena requested documents that were responsive to 19 different document requests, including but not limited to organizational charts, discussions of compliance, physician communications, supplier agreements and correspondence related to payments to physicians. We provided a representative sample of these documents that reflected the richness of the total corpus of documents. It included 1,500 total documents from the closed case: 500 responsive documents and 1,000 non-responsive documents.
We then provided document review instructions for GPT-4 that mirrored the review instructions employed by the attorneys who had reviewed those documents. GPT-4 evaluated each document individually, based on the review instructions, and reported whether the document was responsive according to a scoring system of negative one to four. GPT-4 was told to give a document a “negative one” if the document could not be processed; a “zero” if the document contained non-responsive junk or no useful information; a “one” if the document contained non-responsive or irrelevant information; a “two” if the document was likely responsive or contained partial or somewhat relevant information; a “three” if the document was responsive; and a “four” if the document was responsive and contained direct and strong evidence described in the responsiveness criteria. The experimental prompt also asked GPT-4 to provide an explanation for why the document was responsive by citing text from the document.
The experiment proceeded in two stages: (1) Sidley provided GPT-4 with the same review instructions given to the attorneys and collected data on GPT-4’s performance relative to the human review; (2) Based on initial output from stage one, the prompt for GPT-4 was modified to address ambiguities in the responsiveness criteria, which mirrored a quality control (QC) feedback loop that provided the same additional information given to the contract attorneys outside the original review instructions.
Evaluating GPT-4’s Performance
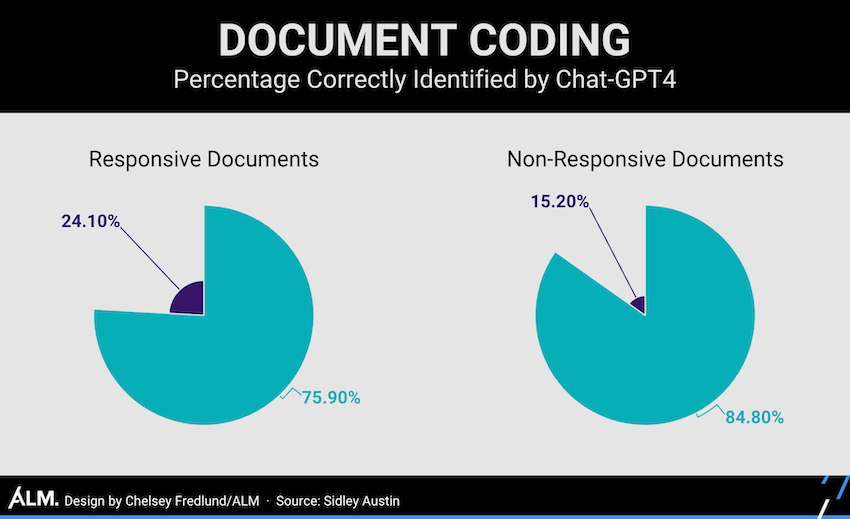
Once these experimental adjustments were made, GPT-4 performed well. Per the chart below, the AI correctly identified, on average, approximately seven out of 10 documents and identified most of the responsive documents.
In general, the results showed that GPT-4 performed well when it was most confident. Where it was highly confident the document contained no relevant information, its performance was quite strong with approximately 85% of documents correctly tagged as non-responsive. Similarly, where it had a high confidence that the document was responsive, its performance was strong with 84% of documents properly tagged. This accuracy at the extremes of its confidence levels indicates that, in its current form, GPT-4 may be reliable as a substitute for human review where it has a high confidence level, subject to validation of its results.
Where GPT-4 was not as confident (i.e., where it returned a score of 2), it tagged 64.5% of documents correctly. A large number of these errors can be attributed to the fact that additional information provided to attorneys during the course of the review was not part of the initial review instructions provided to GPT-4. Once the prompt was revised, there was a much smaller number of documents scored in this range, which led to higher overall recall and precision. This result is not unexpected since attorneys are able to follow up and ask clarifying questions as they arise—a uniquely human task that GPT-4 cannot do.
The research showed that there were limitations to GPT-4’s ability to properly code documents that were part of a responsive family, documents that contained short responsive messages, or documents that had responsive attachments. These limitations are not surprising given that the review instructions provided to GPT-4 related only to the document’s extracted text. It may be possible to direct GPT-4 to evaluate family member documents as part of its analysis, by providing metadata for the family documents and specific review instructions to that effect. But that was not done here. In short, in its current formulation, GPT-4 evaluated each document based only on content within the four corners of the document and was not influenced by context from family member documents or embedded files or links. Traditional tools such as TAR, search terms, and analytics are similarly limited to review based on the four corners of the document, and generally do not incorporate context from family relationships. Based on our research, at this point, a review protocol that incorporates input from human reviewers who are able to analyze these nuances would be the most effective way to evaluate fewer clear-cut documents. For now, GPT-4 may be best suited at paring down the universe of documents that could then be reviewed using traditional tools and manual human review.
Finally, GPT-4 analyzes documents at a much slower pace compared to current TAR tools. We saw speeds of approximately one document per second in our testing. This speed, of course, dwarfs the ability of human reviewers to review documents. But one document/second is still considerably behind TAR, which typically scores hundreds of thousands of documents per hour. Future speed will depend on capacity and throughput and may be substantially faster than during initial testing. In addition, while we expect speeds to improve significantly over time, GPT-4’s current speed limits its application to review populations composed of thousands or tens of thousands of documents, rather than millions.
The Future of GPT-4
Undoubtedly, the future will spell still greater uses for GPT-4. Our experiment leads us to draw two conclusions about its current use. First, GPT-4 operates fundamentally differently than traditional TAR tools. While TAR tools score documents based on the decisions of reviewers on so-called “training” documents, GPT-4 performs independent evaluations of each document against the prompt. Based on our review of the results, this leads to far more consistency in coding than we see traditionally with human review. It also leads to a cleaner and more efficient QC process that would likely change traditional review workflows. Specifically, GPT-4 can generate explanations about its responsiveness determination, which will likely expedite the QC process by allowing a human reviewer to more quickly confirm that a document is responsive.
Second, its performance level was dependent on the quality and completeness of the prompt provided to GPT-4. When GPT-4 was given the same initial review instructions provided to the attorneys that originally coded and tagged the documents, any ambiguity in those instructions showed up in the results. This is not surprising since human reviewers can make inferences and ask clarifying questions that AI cannot, at present. Thus, at least in the near term, practitioners interested in using generative AI for document review should be particularly mindful about ambiguity in their review instructions and provide as much precision and detail as possible.
Colleen Kenney, a partner, is founder and head of Sidley’s eDiscovery and Data Analytics group; Matt Jackson is Counsel focusing on complex electronic discovery matters and all aspects of the Electronic Discovery Reference Model; and Robert D. Keeling, partner and the founder and head of Sidley’s eDiscovery and Data Analytics group.






Leave A Comment